CPUs these days do not just have multiple cores, but nested hierarchies of clusters of cores with their own distinct NUMA memory regions. Some specific and more generic forms of acceleration are etched directly into the cores, just like with single-core CPUs in the old days.
But thanks to the amazing chip transistor densities and chiplet packaging techniques available today, other forms of acceleration are not pushed out to the PCI-Express bus, far away from cores and main memory. Instead, they’re implemented outside the cores but on the core complex chiplets themselves or in distinct chiplets that are interconnected inside the socket package.
To a certain extent, all modern server CPUs have a mix of standard integer and floating-point compute in the cores and other kinds of compute in the non-core regions of the package. And so when comparing processors from different vendors, it is important not to just count cores and clock speeds and the resulting integer and floating point performance on industry standard benchmarks from SPEC. You must look at specific workloads and the extent to which the accelerators inside of the cores, as well as those outside of the cores, work in concert to boost real-world application performance.
A CORNUCOPIA OF ACCELERATORS
Over the years, Intel has been adding greater numbers of more diverse accelerators to its Intel® Xeon® and Intel® Xeon® SP server CPU architectures. This has been driven by the needs of specific applications which Intel has targeted to grow its Xeon and Xeon SP footprint beyond general purpose compute in the datacenter running applications written in C, C++, Java, Fortran, Python, PHP, and other languages. In some cases, the move from datacenter compute into adjacencies such as network function virtualization (NFV) or storage – where custom ASICs have been replaced by X86 CPUs – drove the addition of specific accelerators. The same is true in the HPC simulation and modeling, and AI training and inference, spaces.
As GPUs have been redesigned to support the heavy vector and matrix math used in HPC and AI applications, and custom ASICs have been invented to push performance even further than GPUs, Intel (amongst other server CPU makers) has been fattening up vector engines and allowing them to support lower precision integer and floating-point data to pull some of this HPC and AI work back onto the CPU.
And in more recent processors, matrix math units designed specifically to accelerate the specific low precision matrix math commonly used on AI inference (and sometimes training) are also being added to the compute complex.
With the “Golden Cove” cores used in the “Sapphire Rapids” 4th Gen Intel® Xeon® Scalable processors, the existing AVX-512 math unit has been expanded to include support for accelerating certain math algorithms commonly performed by vRAN software running on 5G network base stations, for example.
The Golden Cove cores also bring a new Intel Advanced Matrix Extensions (AMX) unit, which allows for larger matrices to be added or multiplied in a single operation and that deliver much more throughput than running mixed precision integer operations on the Intel AVX-512 vector unit.
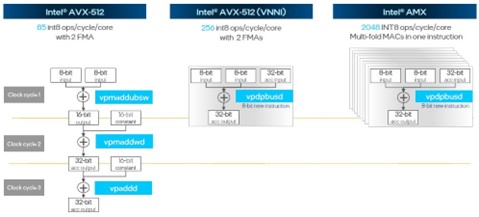
Both the Intel AVX-512 and Intel AMX math units in each core can be used simultaneously – it is not an either/or proposition. But clearly, for relatively small matrices the INT8 performance of the Intel AMX unit, which offers an 8X increase in raw throughput, is going to be compelling, particularly for (but by no means limited to) AI inference work. And given that the natural place to do AI inference is within the CPU where the applications are running, the addition of the Intel AMX accelerator will help Intel protect its AI inference turf. The majority of AI inference is still done on CPUs today, and Intel would like to keep it that way.
We’ll shortly do a deeper dive on running AI inference natively on the Sapphire Rapids CPUs and speak more generically about the performance benefits of these and other accelerators.